47 | 接收网络包(上):如何搞明白合作伙伴让我们做什么?





讲述:刘超
时长12:57大小11.87M
前面两节,我们分析了发送网络包的整个过程。这一节,我们来解析接收网络包的过程。
如果说网络包的发送是从应用层开始,层层调用,一直到网卡驱动程序的话,网络包的结束过程,就是一个反过来的过程,我们不能从应用层的读取开始,而应该从网卡接收到一个网络包开始。我们用两节来解析这个过程,这一节我们从硬件网卡解析到 IP 层,下一节,我们从 IP 层解析到 Socket 层。
设备驱动层
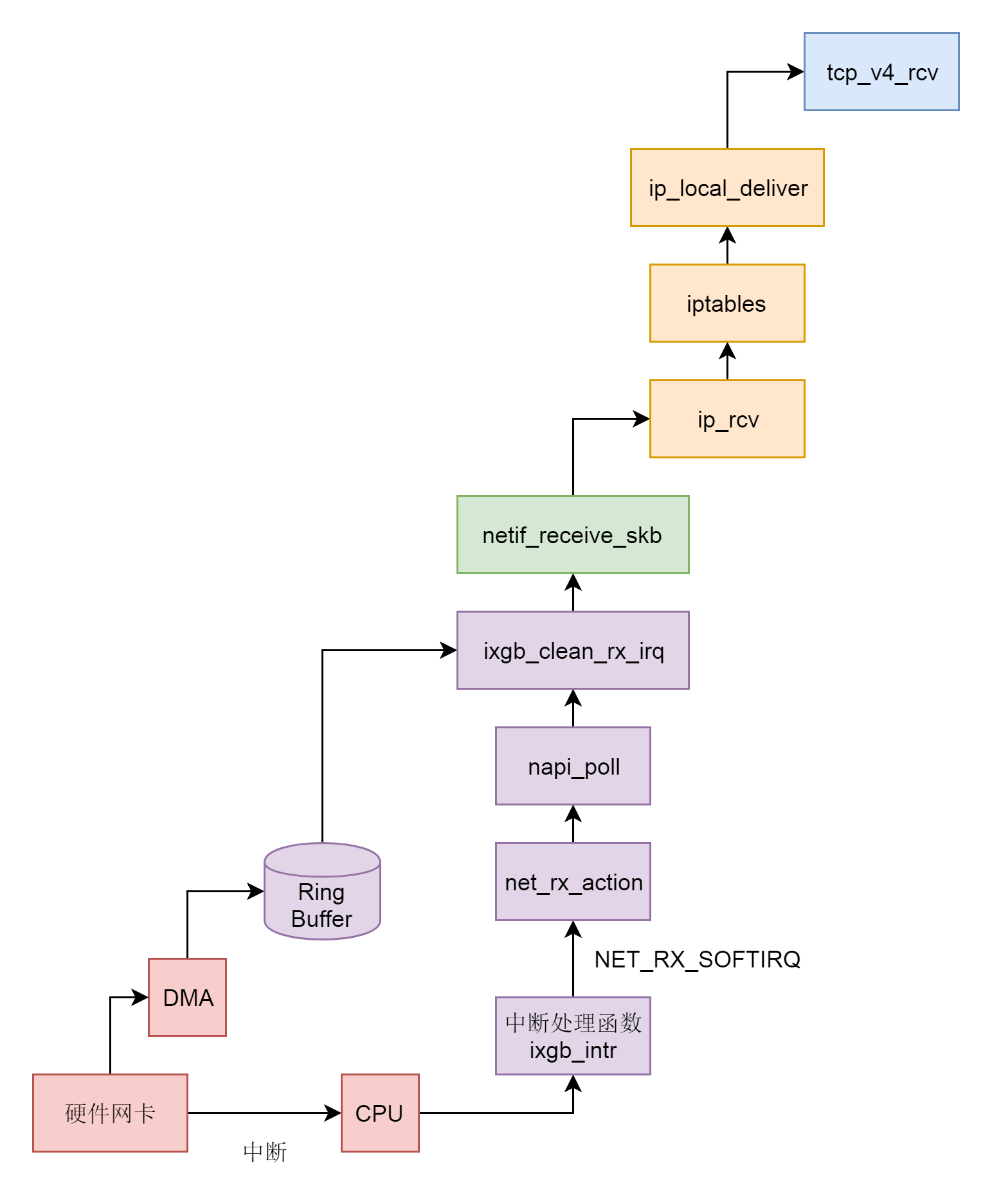
网卡作为一个硬件,接收到网络包,应该怎么通知操作系统,这个网络包到达了呢?咱们学习过输入输出设备和中断。没错,我们可以触发一个中断。但是这里有个问题,就是网络包的到来,往往是很难预期的。网络吞吐量比较大的时候,网络包的到达会十分频繁。这个时候,如果非常频繁地去触发中断,想想就觉得是个灾难。
比如说,CPU 正在做某个事情,一些网络包来了,触发了中断,CPU 停下手里的事情,去处理这些网络包,处理完毕按照中断处理的逻辑,应该回去继续处理其他事情。这个时候,另一些网络包又来了,又触发了中断,CPU 手里的事情还没捂热,又要停下来去处理网络包。能不能大家要来的一起来,把网络包好好处理一把,然后再回去集中处理其他事情呢?
网络包能不能一起来,这个我们没法儿控制,但是我们可以有一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询 poll 网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断,再轮询 poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式我们称为NAPI。
为了帮你了解设备驱动层的工作机制,我们还是以上一节发送网络包时的网卡 drivers/net/ethernet/intel/ixgb/ixgb_main.c 为例子,来进行解析。
在网卡驱动程序初始化的时候,我们会调用 ixgb_init_module,注册一个驱动 ixgb_driver,并且调用它的 probe 函数 ixgb_probe。
在 ixgb_probe 中,我们会创建一个 struct net_device 表示这个网络设备,并且 netif_napi_add 函数为这个网络设备注册一个轮询 poll 函数 ixgb_clean,将来一旦出现网络包的时候,就是要通过他来轮询了。
当一个网卡被激活的时候,我们会调用函数 ixgb_open->ixgb_up,在这里面注册一个硬件的中断处理函数。
如果一个网络包到来,触发了硬件中断,就会调用 ixgb_intr,这里面会调用 __napi_schedule。
__napi_schedule 是处于中断处理的关键部分,在他被调用的时候,中断是暂时关闭的,但是处理网络包是个复杂的过程,需要到延迟处理部分,所以 ____napi_schedule 将当前设备放到 struct softnet_data 结构的 poll_list 里面,说明在延迟处理部分可以接着处理这个 poll_list 里面的网络设备。
然后 ____napi_schedule 触发一个软中断 NET_RX_SOFTIRQ,通过软中断触发中断处理的延迟处理部分,也是常用的手段。
上一节,我们知道,软中断 NET_RX_SOFTIRQ 对应的中断处理函数是 net_rx_action。
在 net_rx_action 中,会得到 struct softnet_data 结构,这个结构在发送的时候我们也遇到过。当时它的 output_queue 用于网络包的发送,这里的 poll_list 用于网络包的接收。
在 net_rx_action 中,接下来是一个循环,在 poll_list 里面取出网络包到达的设备,然后调用 napi_poll 来轮询这些设备,napi_poll 会调用最初设备初始化的时候,注册的 poll 函数,对于 ixgb_driver,对应的函数是 ixgb_clean。
ixgb_clean 会调用 ixgb_clean_rx_irq。
在网络设备的驱动层,有一个用于接收网络包的 rx_ring。它是一个环,从网卡硬件接收的包会放在这个环里面。这个环里面的 buffer_info[] 是一个数组,存放的是网络包的内容。i 和 j 是这个数组的下标,在 ixgb_clean_rx_irq 里面的 while 循环中,依次处理环里面的数据。在这里面,我们看到了 i 和 j 加一之后,如果超过了数组的大小,就跳回下标 0,就说明这是一个环。
ixgb_check_copybreak 函数将 buffer_info 里面的内容,拷贝到 struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用 netif_receive_skb。
网络协议栈的二层逻辑
从 netif_receive_skb 函数开始,我们就进入了内核的网络协议栈。
接下来的调用链为:netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb->__netif_receive_skb_core。
在 __netif_receive_skb_core 中,我们先是处理了二层的一些逻辑。例如,对于 VLAN 的处理,接下来要想办法交给第三层。
在网络包 struct sk_buff 里面,二层的头里面有一个 protocol,表示里面一层,也即三层是什么协议。deliver_ptype_list_skb 在一个协议列表中逐个匹配。如果能够匹配到,就返回。
这些协议的注册在网络协议栈初始化的时候, inet_init 函数调用 dev_add_pack(&ip_packet_type),添加 IP 协议。协议被放在一个链表里面。
假设这个时候的网络包是一个 IP 包,则在这个链表里面一定能够找到 ip_packet_type,在 __netif_receive_skb_core 中会调用 ip_packet_type 的 func 函数。
从上面的定义我们可以看出,接下来,ip_rcv 会被调用。
网络协议栈的 IP 层
从 ip_rcv 函数开始,我们的处理逻辑就从二层到了三层,IP 层。
在 ip_rcv 中,得到 IP 头,然后又遇到了我们见过多次的 NF_HOOK,这次因为是接收网络包,第一个 hook 点是 NF_INET_PRE_ROUTING,也就是 iptables 的 PREROUTING 链。如果里面有规则,则执行规则,然后调用 ip_rcv_finish。
ip_rcv_finish 得到网络包对应的路由表,然后调用 dst_input,在 dst_input 中,调用的是 struct rtable 的成员的 dst 的 input 函数。在 rt_dst_alloc 中,我们可以看到,input 函数指向的是 ip_local_deliver。
在 ip_local_deliver 函数中,如果 IP 层进行了分段,则进行重新的组合。接下来就是我们熟悉的 NF_HOOK。hook 点在 NF_INET_LOCAL_IN,对应 iptables 里面的 INPUT 链。在经过 iptables 规则处理完毕后,我们调用 ip_local_deliver_finish。
在 IP 头中,有一个字段 protocol 用于指定里面一层的协议,在这里应该是 TCP 协议。于是,从 inet_protos 数组中,找出 TCP 协议对应的处理函数。这个数组的定义如下,里面的内容是 struct net_protocol。
在系统初始化的时候,网络协议栈的初始化调用的是 inet_init,它会调用 inet_add_protocol,将 TCP 协议对应的处理函数 tcp_protocol、UDP 协议对应的处理函数 udp_protocol,放到 inet_protos 数组中。
在上面的网络包的接收过程中,会取出 TCP 协议对应的处理函数 tcp_protocol,然后调用 handler 函数,也即 tcp_v4_rcv 函数。
总结时刻
这一节我们讲了接收网络包的上半部分,分以下几个层次。
- 硬件网卡接收到网络包之后,通过 DMA 技术,将网络包放入 Ring Buffer。
- 硬件网卡通过中断通知 CPU 新的网络包的到来。
- 网卡驱动程序会注册中断处理函数 ixgb_intr。
- 中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断 NET_RX_SOFTIRQ 触发接下来的处理过程。
- NET_RX_SOFTIRQ 软中断处理函数 net_rx_action,net_rx_action 会调用 napi_poll,进而调用 ixgb_clean_rx_irq,从 Ring Buffer 中读取数据到内核 struct sk_buff。
- 调用 netif_receive_skb 进入内核网络协议栈,进行一些关于 VLAN 的二层逻辑处理后,调用 ip_rcv 进入三层 IP 层。
- 在 IP 层,会处理 iptables 规则,然后调用 ip_local_deliver,交给更上层 TCP 层。
- 在 TCP 层调用 tcp_v4_rcv。
课堂练习
我们没有仔细分析对于二层 VLAN 的处理,请你研究一下 VLAN 的原理,然后在代码中看一下对于 VLAN 的处理过程,这是一项重要的网络基础知识。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

1716143665 拼课微信(3)
 许童童2019-07-15VLAN 的原理有些忘了,希望老师可以在答疑中给我们答疑一下。
许童童2019-07-15VLAN 的原理有些忘了,希望老师可以在答疑中给我们答疑一下。 Cyril2019-07-15老师能否详细写一点关于 smp 相关的知识,比如多 cpu 如何处理网卡过来的中断,多 cpu 如何进程调度,多 cpu 又是如何解决共享变量访问冲突的问题,对这一部分知识点一直比较模糊
Cyril2019-07-15老师能否详细写一点关于 smp 相关的知识,比如多 cpu 如何处理网卡过来的中断,多 cpu 如何进程调度,多 cpu 又是如何解决共享变量访问冲突的问题,对这一部分知识点一直比较模糊 安排2019-07-15牛展开
安排2019-07-15牛展开


